Change Data Capture

CDC stands for Change data capture, not many developers have heard about it let alone work in a project that requires CDC. According to WikiPedia https://en.wikipedia.org/wiki/Change_data_capture
CDC is an approach to data integration that is based on the identification, capture and delivery of the changes made to enterprise data sources.
Almost all kinds of applications directly or indirectly will need to have a CDC system. All applications store data in a database and this data will need to be transformed and transmitted to other systems for a variety of reasons. Take for example a banking application that stores customer daily transactions data, these data will need to be converted and stored into different systems used to produce regulatory reporting. The same data will be needed to be stored in a data warehouse that will allow the credit department to know how much money the bank has left that can be used in the debt market.
Having a CDC system in place will make it easy for data to be used in different forms that can bring business value to the enterprise.
We will look at CDC from a technical point of view and in the next section we will look at different ways CDC can be implemented.
Variety of CDC
There are multiple common Change Data Capture methods that you can implement depending on your requirements and other factors such as performance. For this article we will focus on how to use CDC to stream data from a database and convert the data to be used in different systems.
Following are the different methods available for implementing CDC system:
Trigger-based CDC - This CDC relies on writing functions specific to the database to be triggered when data changes occurred in the database. This requires understanding the context of the data.
Log-based CDC - DBMS has an internal log that it uses to record data changes that are made to tables. Log based CDC utilizes this internal DBMS log data to capture data and send it to different systems. This kind of CDC does not have any knowledge of the context of the data that are being read and sent unlike the other CDC methods.
Query-based CDC - This method of CDC system requires knowledge about the source of data that we are interested in using. This model is quite invasive as deep understanding of the data domain is required including the SQL used to query the data.
We'll examine two approaches to gain a deeper comprehension of their functioning and observe technical implementations through examples.
Trigger based
An internal database feature called trigger (or trigger functions) is utilized in a trigger-based CDC system. This type of system is available in all relational database management systems (RDBMS), which are the commonly used databases in data-driven applications.
Database trigger
A trigger is essentially a SQL function that executes within the database environment. It is activated in response to specific events occurring in the database, such as the creation of a new record in a table, and can be used to create an audit log in a separate table. Here's an example of a trigger function that creates a new entry in an audit_log table when there is an INSERT, UPDATE or DELETE operation on a table:
CREATE OR REPLACE FUNCTION audit_trigger()
RETURNS trigger AS $$
DECLARE
old_row json := NULL;
new_row json := NULL;
BEGIN
IF TG_OP IN ('UPDATE','DELETE') THEN
old_row = row_to_json(OLD);
END IF;
IF TG_OP IN ('INSERT','UPDATE') THEN
new_row = row_to_json(NEW);
END IF;
INSERT INTO audit_log(
username,
event_time_utc,
table_name,
operation,
before_value,
after_value
) VALUES (
session_user,
current_timestamp AT TIME ZONE 'UTC',
TG_TABLE_SCHEMA || '.' || TG_TABLE_NAME,
TG_OP,
old_row,
new_row
);
RETURN NEW;
END;
$$ LANGUAGE plpgsql;Here's an example of how to set up the RDBMS to associate the trigger function with an INSERT, UPDATE, or DELETE operation, so that it is invoked every time a new row is inserted, an existing row is updated, or an existing row is deleted:
CREATE TRIGGER audit_log
AFTER INSERT OR UPDATE OR DELETE
ON notify
FOR EACH ROW
EXECUTE PROCEDURE audit_trigger();Configuring trigger using Go
It's clear that we can generate triggers in a database to perform supplementary tasks when particular data operations take place on a table. Let's now investigate how to establish these triggers using Go. Our focus will be on a user-friendly project that provides this feature, as well as a basic web UI. You can find the project at http://github.com/inqueryio/inquery.
In this section, we won't delve into the details of configuring Inquery. For more information on installing it locally, you can refer to the instructions provided on their documentation website at https://docs.inquery.io/overview/introduction.
The Inquery project showcases a simple approach to configuring a CDC system. It configures the specified table and, depending on the parameters chosen, transmits insert, update, and delete changes to a chosen endpoint. The following diagram illustrates the entire process of how Inquery accomplishes this data flow between Postgres and our data endpoint.
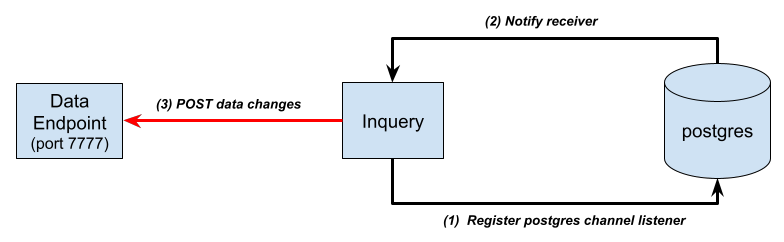
Figure 1 - Inquery High Level Flow
Following outlined the different steps that happens:
(1) Inquery will install a trigger function on the table specified by the user, including the data operation that it is interested in - INSERT, UPDATE and DELETE. Along with the trigger it will register a channel to Postgres that is used to send the data changes.
(2) Inquery received notification from Postgres through the channel registered earlier. The notification contain information about data changes, containing both old and new data
(3) Every time Inquery receives notification it will format the data based on the template that has been defined by the user and send it to the data endpoint using HTTP POST. In the diagram shown the endpoint is listening on port 7777
The following shows the function that will be called when the data operation trigger happens.
create function pg_notify_trigger_event_public_car() returns trigger
language plpgsql
as
$$
declare
hasNew bool = false;
hasOld bool = false;
payload jsonb;
begin
if TG_OP = 'INSERT' then
hasNew = true;
elseif TG_OP = 'UPDATE' then
hasNew = true;
hasOld = true;
else
hasOld = true;
end if;
payload = jsonb_build_object(
'table', TG_TABLE_NAME,
'schema', TG_TABLE_SCHEMA,
'event', to_jsonb(TG_OP)
);
if hasNew then
payload = jsonb_set(payload, '{new}', to_jsonb(NEW), true);
end if;
if hasOld then
payload = jsonb_set(payload, '{old}', to_jsonb(OLD), true);
end if;
perform pg_notify('pg_notify_trigger_event', payload::text);
return NEW;
end;
$$;
alter function pg_notify_trigger_event_public_car() owner to nanik;The following screenshot shows the 3 different triggers that are configured by Inquery for the car table. The triggers are configured for DELETE, INSERT and UPDATE operation that will call the same pg_notify_trigger_event_public_car function.
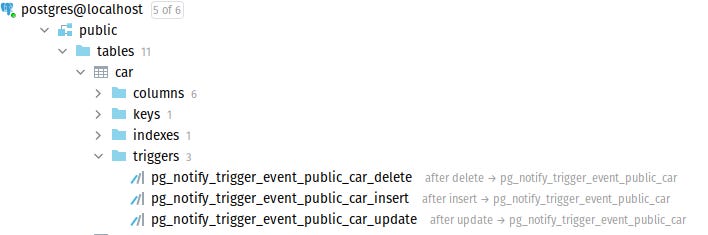
Figure 2 - Trigger functions created by Inquery
The example explained in this section will be using the table that store car information, below is the DDL for the table, in my example the table is stored inside database called car
create table public.car
(
car_id integer not null primary key,
serial_no varchar not null,
make varchar not null,
model varchar not null,
color varchar not null,
year integer not null
);The following is the configuration that is setup in Inquery for the table
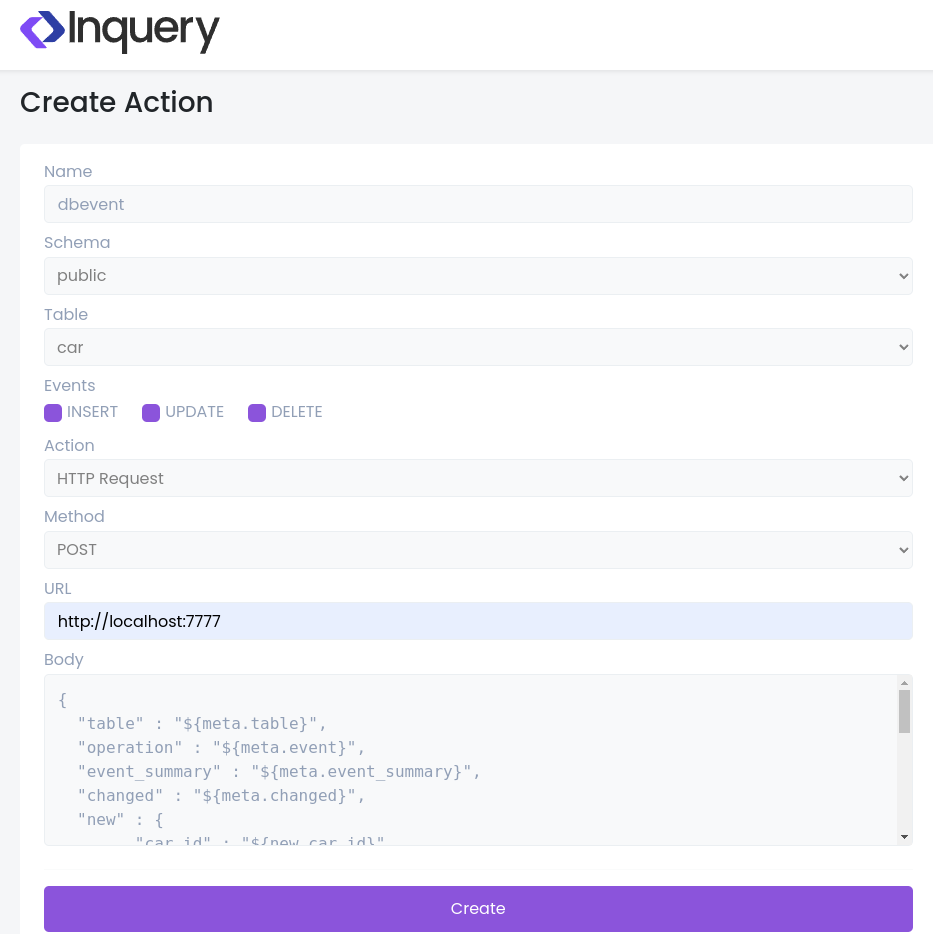
Figure 3 - Inquery Web UI
The complete template used to send the data from Inquery to out endpoint on port 7777 is as shown
{
"table" : "${meta.table}",
"operation" : "${meta.event}",
"event_summary" : "${meta.event_summary}",
"changed" : "${meta.changed}",
"new" : {
"car_id" : "${new.car_id}",
"color" : "${new.color}",
"make" : "${new.make}",
"model" : "${new.model}",
"serial_no" : "${new.serial_no}",
"year" : "${new.year}"
},
"old" : {
"car_id" : "${old.car_id}",
"color" : "${old.color}",
"make" : "${old.make}",
"model" : "${old.model}",
"serial_no" : "${old.serial_no}",
"year" : "${old.year}"
}
}The application that is listening for the CDC data on port 7777 is as follows:
package main
import (
"encoding/json"
"fmt"
"log"
"net/http"
)
type DBEvent struct {
Table string `json:"table"`
Operation string `json:"operation"`
EventSummary string `json:"event_summary"`
Changed string `json:"changed"`
New struct {
CarID string `json:"car_id"`
Color string `json:"color"`
Make string `json:"make"`
Model string `json:"model"`
SerialNo string `json:"serial_no"`
Year string `json:"year"`
} `json:"new"`
Old struct {
CarID string `json:"car_id"`
Color string `json:"color"`
Make string `json:"make"`
Model string `json:"model"`
SerialNo string `json:"serial_no"`
Year string `json:"year"`
} `json:"old"`
}
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
if r.Method == "POST" {
decoder := json.NewDecoder(r.Body)
var data DBEvent
err := decoder.Decode(&data)
if err != nil {
http.Error(w, err.Error(), http.StatusBadRequest)
return
}
fmt.Printf("Received JSON: %+v\n", data)
w.WriteHeader(http.StatusOK)
return
}
http.Error(w, "Invalid request method", http.StatusMethodNotAllowed)
return
})
log.Fatal(http.ListenAndServe(":7777", nil))
}On completing running the application and creating the configuration in Inquery, now every time you perform any data operation to the car table the application will get notified as shown in the output below
Received JSON: {Table:car Operation:DELETE EventSummary: Changed: New:{CarID: Color: Make: Model: SerialNo: Year:} Old:{CarID:2 Color:asd Make:b123 Model:asd SerialNo:a123 Year:2023}}
Received JSON: {Table:car Operation:INSERT EventSummary: Changed: New:{CarID:2 Color:ii Make:gg Model:hh SerialNo:ff Year:2021} Old:{CarID: Color: Make: Model: SerialNo: Year:}}
Received JSON: {Table:car Operation:UPDATE EventSummary: Changed: New:{CarID:2 Color:ii Make:gg Model:hh SerialNo:gg Year:2021} Old:{CarID:2 Color:ii Make:gg Model:hh SerialNo:ff Year:2021}}
Received JSON: {Table:car Operation:UPDATE EventSummary: Changed: New:{CarID:4 Color:d2 Make:b1 Model:c1 SerialNo:adsadad Year:2023} Old:{CarID:4 Color:d2 Make:b1 Model:c1 SerialNo:a2 Year:2023}}
Received JSON: {Table:car Operation:UPDATE EventSummary: Changed: New:{CarID:1 Color:d Make:a Model:c SerialNo:adsada Year:1970} Old:{CarID:1 Color:d Make:a Model:c SerialNo:bb Year:1970}}
...Looking at the log above we can see when UPDATE operation is performed the JSON sends both new and old data, which will help the application to decide what to do when values are modified. In the log we can also see INSERT operation data where the data is inside the New field.
Log based
Log-based Change Data Capture (CDC) is a technique used to capture changes in a database system by monitoring the transaction log of the database. It is a popular method used to replicate data from one database to another. In traditional replication methods, changes are captured by polling the database for changes using a timestamp or some other mechanism. With log-based CDC, changes are captured in real-time as they occur.
Log-based CDC works by monitoring the transaction log of the source database for changes. When a change occurs, the CDC process reads the transaction log and extracts the relevant information.
System Design
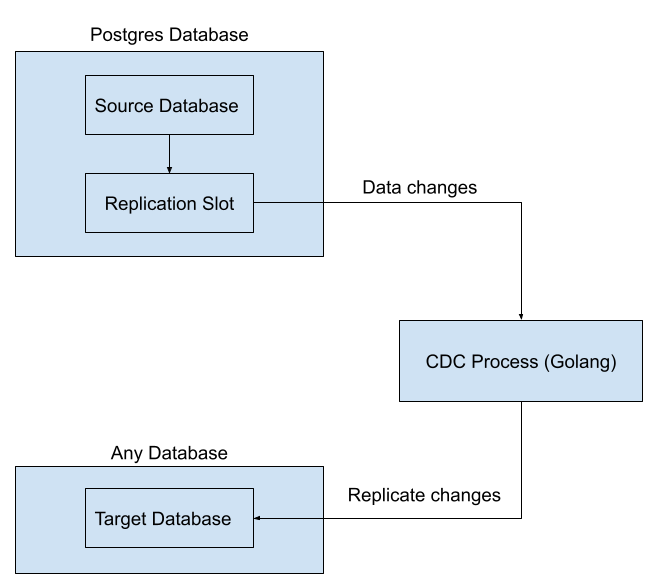
Figure 4 - Log based CDC System
Figure 4 shows at the high level how the CDC system setup looks like. Following explains the role each different sub-system plays:
The source database, in this example is a Postgres database, is the database from which changes need to be replicated.
The replication slot is the channel that changes are being communicated internally in Postgres
The CDC process monitors via the replication slot for any changes made to the source database.
The CDC process extracts the relevant information and transforms it into a format that can be loaded into the target database.
The target database is the database to which the changes need to be replicated.
The transformed data is loaded into the target database, either in bulk or individually.
Let’s take a look now on how to setup this kind of configuration
Database Setup
In this section we will look at a local example setup where we are going to run Postgres as a source database and have a CDC process in Golang that will configure and connect the replication slot to read data changes. The received data changes will be printed into the console.
Use docker to run postgres locally to listen on port 8888 as follows:
docker run -p 8888:5432 -e POSTGRES_USER=admin -e POSTGRES_PASSWORD=password -e POSTGRES_DB=postgres postgres -c wal_level=logicalFollowing explained the docker commands:
-p 8888:5432: This option maps the container's port 5432, which is the default port for PostgreSQL, to the host's port 8888, allowing you to access the PostgreSQL server from your host machine.
-e POSTGRES_USER=admin: This option sets the username for the default PostgreSQL user to "admin".
-e POSTGRES_PASSWORD=password: This option sets the password for the default PostgreSQL user to "password".
-e POSTGRES_DB=postgres: This option sets the name of the default database to "postgres".
postgres: This is the name of the Docker image for the PostgreSQL database.
-c wal_level=logical: This option sets the wal_level configuration parameter for the PostgreSQL server to logical, which enables logical replication.
Once Postgres database is up and running use any SQL client tool to connect to the database and run the following DDL statement:
create table if not exists public.car
(
car_id integer generated by default as identity
primary key,
serial_no varchar not null,
make varchar not null,
model varchar not null,
color varchar not null,
year integer not null
);
alter table public.car
owner to admin;
ALTER TABLE public.car REPLICA IDENTITY FULL;The DDL script creates a table car and configures the table with REPLICA IDENTITY FULL. By setting the replica identity to FULL, all columns in the table are included in the replica identity, which can ensure that updates or deletes can be correctly propagated.
CDC Application
Now that the source database is ready we need to run the CDC application, in this case the Go program that we are going to run can be cloned from https://github.com/nanikjava/wal. Run the application as normal Go application
go run main.goThe application is now ready to listen and will print out frequently the following message on the console, indicating that the connection to the replication slot is active.
…
server: confirmed standby
server: confirmed standby
…If you now you make any changes to the car table you will see all those changes printed in the application console, following shows example output of insert, update and delete operation performed on the table
…
server: confirmed standby
2023/03/26 19:37:52 Relation 16384 car has 6 columns
UPDATE car(New car_id: 2 New serial_no: Nanik New make: Make New model: 121212121 New color: ads New year: 2000 )
UPDATE car(Old car_id: 2 Old serial_no: eeeeadsdad Old make: car Old model: 121212121 Old color: ads Old year: 2000 )
server: confirmed standby
…
INSERT car(car_id: 5 serial_no: New make: MakeNew model: MOdelNew color: Blue year: 2022 )
…
DELETE car(car_id: 5 serial_no: New make: MakeNew model: MOdelNew color: Blue year: 2022 )
server: confirmed standby
…We now have an end-to-end CDC system running.
How does it work ?
The CDC (Change Data Capture) application is designed to capture all changes made to a source PostgreSQL database and transfer them to a target database or external system in near-real-time. To achieve this, the application leverages the Logical Replication feature provided by PostgreSQL.
To capture all changes, the application uses a replication slot, which is a named object that stores replication information. The replication slot is created and configured using the pglogrepl (github.com/jackc/pglogrepl) library, which uses its internal library to communicate with the PostgreSQL database.
The pglogrepl library is built on top of the pgx library, which implements the PostgreSQL replication protocol outlined in the official PostgreSQL documentation - https://www.postgresql.org/docs/current/protocol-logical-replication.html. This protocol is used by the library to parse replication messages received from the replication slot.
The replication messages contain information about the changes made to the source database - columns and the data before and after the change. The application parses these messages using the pglogrepl library and transforms the data into a format suitable for the target database or external system. Once the data is transformed, the application can then send it to the target database or external system using a suitable connector or driver. This enables the target database or external system to receive the data changes in near-real-time and apply them as needed.
Creating and configuring replication slot
The following code snippet shows the creation of publication.
package main
import (
...
"github.com/jackc/pglogrepl"
"github.com/jackc/pgx/v5/pgconn"
"github.com/jackc/pgx/v5/pgproto3"
...
)
const CONN = "postgres://admin:password@localhost:8888/postgres?replication=database"
...
func main() {
...
//2. Create PUBLICATION
if _, err := conn.Exec(ctx, "CREATE PUBLICATION carpub FOR TABLE car;").ReadAll(); err != nil {
fmt.Printf("failed to create publication: %v", err)
}
…A publication is a set of tables or database objects that are made available for replication to one or more subscribers. The subscriber then subscribes to the publication, and any changes made to the publication are replicated to the subscriber in near-real-time.
The following code snippet shows the creation of the replication slot. The replication slot name is configured inside SLOT_NAME
...
// 3. Create replication slot
if _, err = pglogrepl.CreateReplicationSlot(ctx, conn, SLOT_NAME, OUTPUT_PLUGIN, pglogrepl.CreateReplicationSlotOptions{Temporary: true}); err != nil {
fmt.Printf("failed to create a replication slot: %v", err)
}Once replication slot has been setup the final step would be to inform Postgres to start replication passing it the publication name parameter called carpub
...
var msgPointer pglogrepl.LSN
pluginArguments := []string{"proto_version '1'", "publication_names 'carpub'"}
// 4. Start replication process
err = pglogrepl.StartReplication(ctx, conn, SLOT_NAME, msgPointer, pglogrepl.StartReplicationOptions{PluginArgs: pluginArguments})
if err != nil {
fmt.Printf("failed to establish start replication: %v", err)
}
...We have completed configuring the replication slot from the application.
Parsing replication message and transforming data
Replication has been configured so now the application is ready to accept replication messages, this is where we need to disassemble the different replication messages that will be sent by Postgres. In this section we will not look at all the different messages, we will look at the update message shown in the code snippet below:
switch msg := msg.(type) {
case *pgproto3.CopyData:
switch msg.Data[0] {
...
case pglogrepl.XLogDataByteID:
...
var msg pglogrepl.Message
...
switch m := msg.(type) {
...
case *pglogrepl.UpdateMessage:
var sb strings.Builder
sb.WriteString(fmt.Sprintf("UPDATE %s(", Event.Relation))
for i := 0; i < len(Event.Columns); i++ {
sb.WriteString(fmt.Sprintf("New %s: %s ", Event.Columns[i], string(m.NewTuple.Columns[i].Data)))
}
sb.WriteString(")")
fmt.Println(sb.String())
sb.Reset()
sb.WriteString(fmt.Sprintf("UPDATE %s(", Event.Relation))
for i := 0; i < len(Event.Columns); i++ {
sb.WriteString(fmt.Sprintf("Old %s: %s ", Event.Columns[i], string(m.OldTuple.Columns[i].Data)))
}
sb.WriteString(")")
fmt.Println(sb.String())
...
}When the code detects that the message is of type pglorepl.UpdateMessage it will collect the old and new data which is made available inside NewTuple (for new data) and OldTuple (for old data) fields. The code prints out both the new and old data.
Sending both the new and old data, including the primary key will assist the CDC application to make a decision which field will need to be used/transformed for the target database.
Conclusion
In conclusion, Change Data Capture (CDC) is a process of capturing and tracking changes made to a database over time. CDC is an important feature for applications that need to replicate data between databases or integrate data with other systems.
PostgreSQL provides a powerful CDC feature called Logical Replication, which allows replicating specific tables, columns, or even rows between PostgreSQL instances. CDC application leverages this feature to capture all changes made to a source PostgreSQL database and transfer them to a target database or external system in near-real-time.
Some use cases examples for CDC:
Real-time analytics - CDC can be used to capture changes made to a database and transfer them in real-time to an analytics system.
Data replication - CDC can be used to replicate data between databases or systems. This is useful for applications that need to keep multiple databases in sync or need to transfer data between different systems, even for horizontal scaling.
Auditing and compliance - CDC can be used to capture and track changes made to a database, which is important for auditing and compliance purposes.
ETL processing - CDC can be used to capture changes made to a database and transform them into a format suitable for loading into a data warehouse or other system.